
Can you walk and chew gum at the same time?
Multitasking, according to the Merriman-Webster dictionary, is performing multiple tasks at one time. We all multitask as part of our everyday lives. We cook while we talk on our phone; we watch TV while we catch up on emails; we exercise while commuting to work.
When it comes to database engines, multitasking is essential. Multitasking enables many different user-submitted jobs to run concurrently. Without multitasking capabilities inside the engine, Teradata Vantage would not be able to support hundreds or thousands of user queries at the same time.
Multitasking, according to the Merriman-Webster dictionary, is performing multiple tasks at one time. We all multitask as part of our everyday lives. We cook while we talk on our phone; we watch TV while we catch up on emails; we exercise while commuting to work.
When it comes to database engines, multitasking is essential. Multitasking enables many different user-submitted jobs to run concurrently. Without multitasking capabilities inside the engine, Teradata Vantage would not be able to support hundreds or thousands of user queries at the same time.
While concurrent query execution is the most obvious illustration of a database working on multiple different things in combination, there is another dimension of multitasking that takes place inside Vantage. In this form of multitasking, the database optimizer builds parallel steps into a single query's execution plan.

Each optimized query step is sent as a message from the parsing engine (the virtual processor that performs optimization) to the AMPs (the virtual processors that execute the step in parallel), usually one step at a time. All AMPs involved on that request work on that step in parallel. Only when the first step completes across all AMPs, will the next step be sent.
At the end of each step, all AMPs working on a step have to talk to each other and figure out when they have all completed the step and are ready for the next step. Breaking a query into several big steps instead of hundreds of tiny steps reduces the communication overhead between AMPs.
The less coordination between AMPs that is required during query processing, the more efficient the query will be. A description of how the database manages end-of-step completion is covered in the white paper Born to be Parallel and Beyond, in the section titled Semaphores.
This is like walking into a beauty salon and getting a manicure and a pedicure, both at the same time. Because those activities have no dependency between them they can be performed concurrently by different people. However, you can't expect to get your hair styled at the same time as you do a photo-op, because the photo-op depends on your hair work already being complete.
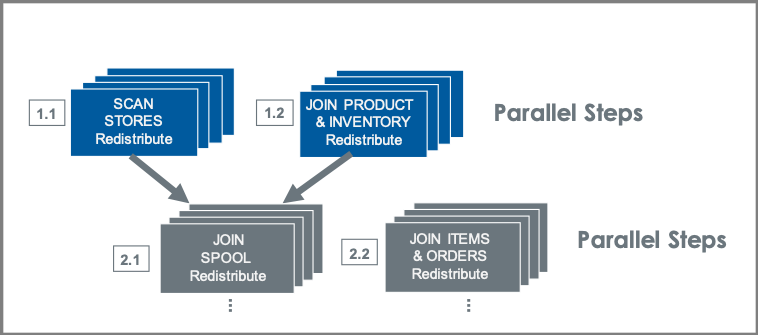
Below is an example of what a query plan might look like that uses parallel steps.
.png?origin=fd "Picture1-(1).png")
In the graphic above, Step 1.1 can be done at the same time as Step 1.2 because they are completely independent of each other. Step 2.1 requires the completion of Step 1.1. and 1.2 because it joins the output of both of those steps, so it can only be executed when the two previous steps complete. Going down a level, Step 2.1 and 2.2 are completely independent one from the other and for that reason they can be executed in parallel.
Don't be confused between parallel query execution and parallel steps. They are two different things. Parallel query execution is the basic parallelism we think of when we think of Teradata, where all AMPs are working on each query step at the same time. Parallel steps add another dimension of parallelism on top of basic query parallelism. With parallel steps, each AMP works on more than one step for the same query at the same time. Parallel steps do not replace query parallelism, they augment it.
As a consequence of parallel steps, a query is often able to consume a higher level of resources and complete sooner. Going back to our nail salon example, you can get out of the salon in half the time if you get the pedicure and the manicure at the same time.
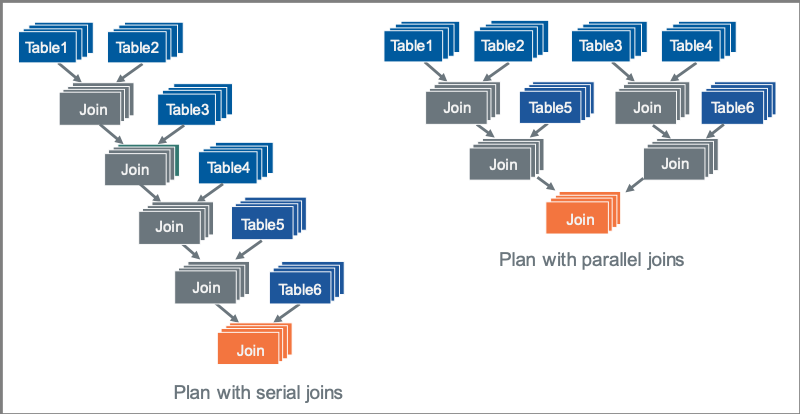
The Vantage optimizer looks at many possible opportunities to multitask when building a query plan. It often produces what are referred to as "bushy plans", plans that make generous use of parallel steps, as illustrated on the right side of the graphic below. This is opposed to more traditional plans that use serial joins.
.png?origin=fd "Picture1-(2).png")
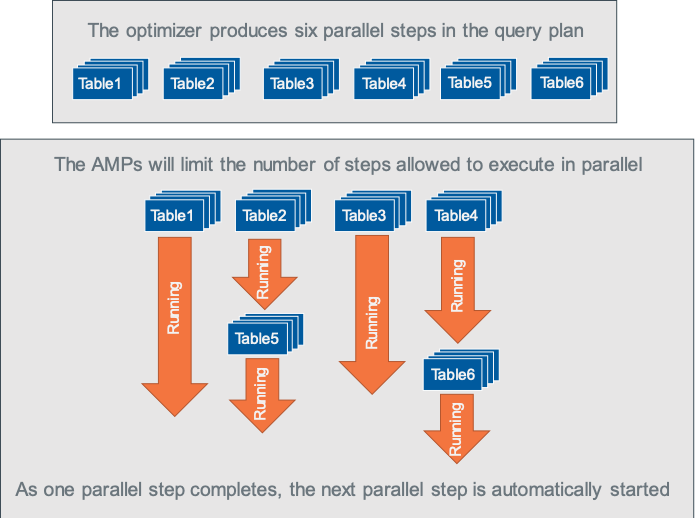
In Vantage, the checks and balances on parallel step multitasking are imposed by the AMPs at the time the query executes. The optimizer may create 10 parallel steps in a query plan, but the AMPs that do the actual execution have various built-in techniques to inhibit more than three or four of those steps from executing at the same time. This prevents an unbalanced demand for resources by any one query. Going back to our nail salon, what if all stylists were grooming a single person to get them through quickly. New customers who walk in could not be serviced. A better business model balances quick service for one person against the need to service multiple customers at the same time. That is the same fairness at work inside the database.
.png?origin=fd "Picture1-(3).png")
Parallelism is at the foundation of Teradata's query performance. But parallelism is exhibited in more ways than just splitting the query's work across multiple AMPs. Parallelism is also imposed within a query itself when the optimizer builds a plan that directs different steps to execute at the same time, in parallel. The result is faster query execution, and more complete usage of the platform resources.
What is a Query Step?
Before exploring parallel steps, let's focus on what a query step is. When the Vantage Optimizer builds a query plan, it breaks the work to be done into large chunks called "steps.” For example, a single query step could read both the Product and the Inventory table, apply predicate conditions on each, join the associated rows, and redistribute the joined rows to different AMPs in preparation for a further join in a later step.Each optimized query step is sent as a message from the parsing engine (the virtual processor that performs optimization) to the AMPs (the virtual processors that execute the step in parallel), usually one step at a time. All AMPs involved on that request work on that step in parallel. Only when the first step completes across all AMPs, will the next step be sent.
At the end of each step, all AMPs working on a step have to talk to each other and figure out when they have all completed the step and are ready for the next step. Breaking a query into several big steps instead of hundreds of tiny steps reduces the communication overhead between AMPs.
The less coordination between AMPs that is required during query processing, the more efficient the query will be. A description of how the database manages end-of-step completion is covered in the white paper Born to be Parallel and Beyond, in the section titled Semaphores.
Parallel Steps
The optimizer can speed up query completion by executing two or more query steps within a query plan at the same time, which is where the additional dimension of multitasking comes in. When the optimizer is producing a query plan, it checks to see if a new step is dependent on the step that came before. If there is no dependency among a set of steps, the optimizer will plan for those steps to be executed in parallel. Consider a query that starts off with four steps that scan each of four different tables. Those scans could be accomplished as four parallel steps, each step running at the same time as the other steps.This is like walking into a beauty salon and getting a manicure and a pedicure, both at the same time. Because those activities have no dependency between them they can be performed concurrently by different people. However, you can't expect to get your hair styled at the same time as you do a photo-op, because the photo-op depends on your hair work already being complete.
Below is an example of what a query plan might look like that uses parallel steps.
In the graphic above, Step 1.1 can be done at the same time as Step 1.2 because they are completely independent of each other. Step 2.1 requires the completion of Step 1.1. and 1.2 because it joins the output of both of those steps, so it can only be executed when the two previous steps complete. Going down a level, Step 2.1 and 2.2 are completely independent one from the other and for that reason they can be executed in parallel.
Don't be confused between parallel query execution and parallel steps. They are two different things. Parallel query execution is the basic parallelism we think of when we think of Teradata, where all AMPs are working on each query step at the same time. Parallel steps add another dimension of parallelism on top of basic query parallelism. With parallel steps, each AMP works on more than one step for the same query at the same time. Parallel steps do not replace query parallelism, they augment it.
As a consequence of parallel steps, a query is often able to consume a higher level of resources and complete sooner. Going back to our nail salon example, you can get out of the salon in half the time if you get the pedicure and the manicure at the same time.
The Vantage optimizer looks at many possible opportunities to multitask when building a query plan. It often produces what are referred to as "bushy plans", plans that make generous use of parallel steps, as illustrated on the right side of the graphic below. This is opposed to more traditional plans that use serial joins.
Too Much of a Good Thing
A good meal is enjoyable and healthy. But if you attempt to eat three or four good meals at the same time the experience will be less enjoyable and long-term may hurt your health. All good things need checks and balances to avoid extremes.In Vantage, the checks and balances on parallel step multitasking are imposed by the AMPs at the time the query executes. The optimizer may create 10 parallel steps in a query plan, but the AMPs that do the actual execution have various built-in techniques to inhibit more than three or four of those steps from executing at the same time. This prevents an unbalanced demand for resources by any one query. Going back to our nail salon, what if all stylists were grooming a single person to get them through quickly. New customers who walk in could not be serviced. A better business model balances quick service for one person against the need to service multiple customers at the same time. That is the same fairness at work inside the database.
Parallelism is at the foundation of Teradata's query performance. But parallelism is exhibited in more ways than just splitting the query's work across multiple AMPs. Parallelism is also imposed within a query itself when the optimizer builds a plan that directs different steps to execute at the same time, in parallel. The result is faster query execution, and more complete usage of the platform resources.